Q&A and personal notes
Before you study this post, please read this Instruction first.
MIG 相關問題整理
Instruction裡面似乎沒有提到如何操作多張GPU,裡面的example都是單張GPU的切割示範,因此是否能提供範例如何操作多張GPU的MIG流程?(這部份很重要)
Ans: 使用
-i做控制。承接上題,例如像我們Server有五張A100,因此總共有將近200GB的Memory可以使用,可否全部融合之後做切割?例如切割單個Instance擁有100GB的這種操作?
Ans: 不行,目前不能融合,只能單張分割。(未來不確定N家是否會開發此相關技術。)
查尋GI模式時,有發現
3g.20gb和4g.20gb兩種instance profiles。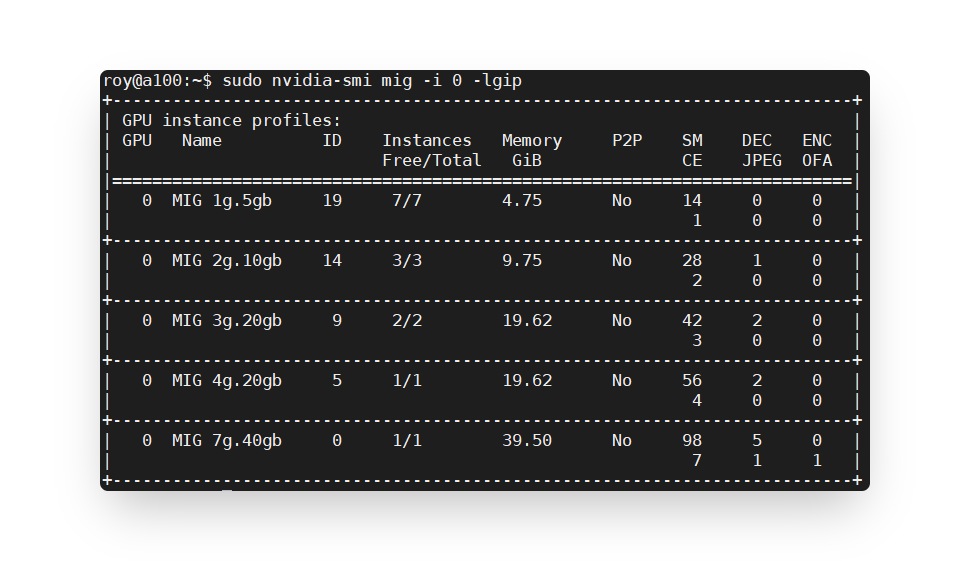
兩個的總Memory都顯示為19.62,但為什麼
4g.20gb的Instance Free/Total 會比3g.20gb的還少?主要差別在哪裡?(4g為1/1,3g為2/2)Ans: 前面的3g和4g代表著各自的算力,4g的算力比3g更強。4g擁有的sm為56,3g擁有的sm為42。在A100裡面每張有98計算單元,切割為7等分(此數據為A100)。基本上1g=14個sm,而
Instance Free/Total的4g較3g少的原因就是算力問題,4g無法搭配到2組,會超出A100的98計算單元(Streaming Multiprocessor)。雖然查看了官網提供的user guide,裡面有介紹有關Device Names的解釋,如下圖

但還是不清楚前者1g,2g,3g的意義為何?
Ans: 前面的g值,數字越大即算力越大。每個的算力可以用nvidia-smi做查看。
根據上圖,在切割上,我知道
3g.20gb的Number of Instances Available是2,因此其可以擁有兩個3g.20gb,而雖然4g.20gb的Number of Instances Available為1,那為什麼不能有1個4g.20gb和1個3g.20gb的搭配?(或其實可以,但並未填入table內而已?)Ans: 於第三題已回答,不可以原因是算力因素。而為何4g不能與3g搭配,N家意思是目前為硬體因素限制,未來可能有機會排除此問題。因此暫時不能有此組合。

(Reference: link)
根據
使用MIG裡面切割了一個2g.10gb、三個1c.3g.20gb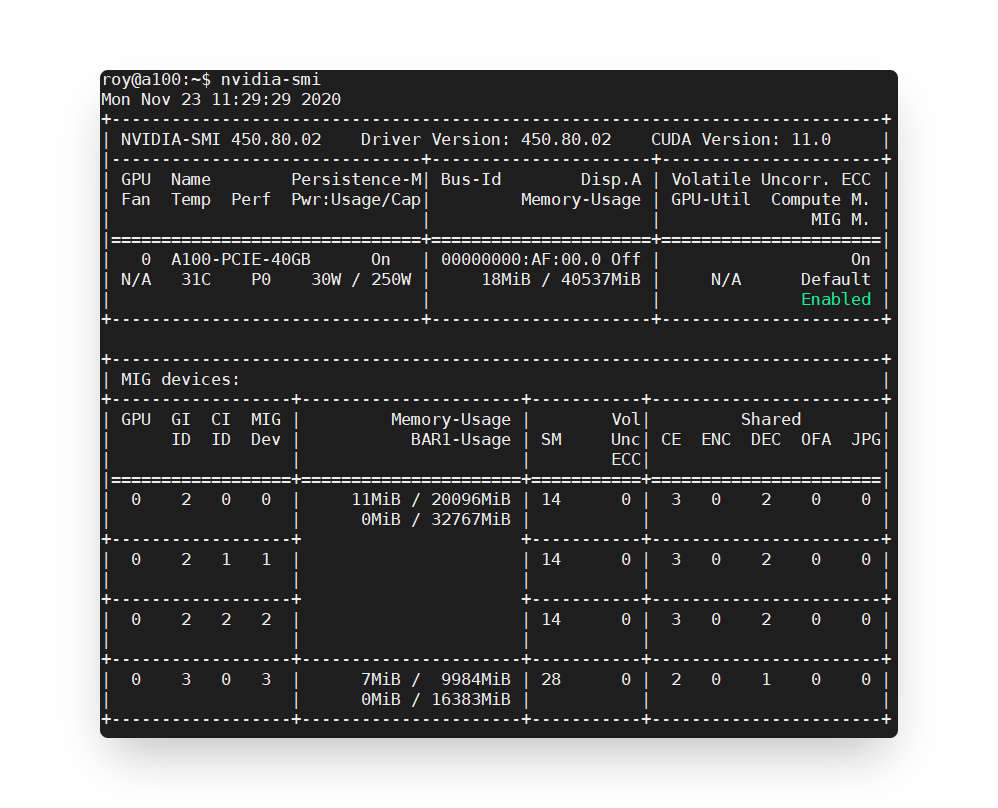
終端器上顯示在Memory-Usage/Bar1-Usage的區塊,想請問Bar1-Usage是什麼?其數值從何取得?
Ans: 於影片(27:26解答),一般上方為GPU真實記憶體,而Bar1-Usage每張gpu都有,其值可從
nvidia-smi -q去查詢每張gpu的bar1 memory usage的值,A100大約為65G左右。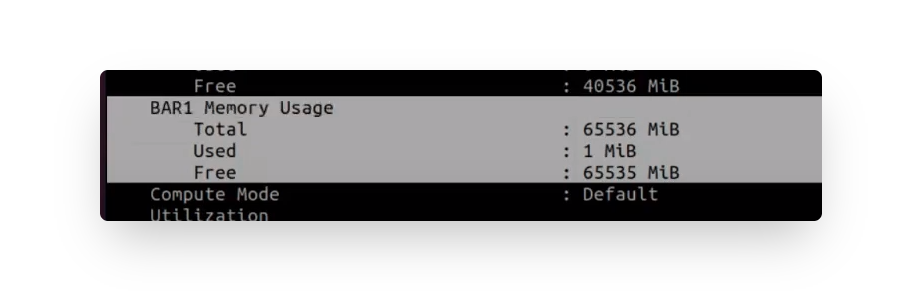
而真實記憶體值可從此看:
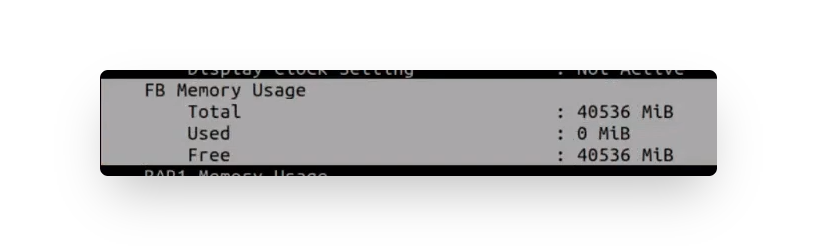
而Bar1-Usage主要是給做PCIE記憶體(虛擬)映射,此值PCIE自己會做分配的。
假若是多張GPU,在使用docker時指定gpu部份,舉例有2張GPU(分別為0,1),且
GPU 0一樣也切割了多個GI與CI的時候,而在MIG Dev部份,數字會是連續的嗎?還是MIG Dev的number是每張GPU從0開始?這會影響我們在操作docker時assign GPU的部份。For example:
sudo docker run -it --rm --gpus '"device=0:0,1:4"' nvcr.io/nvidia/tensorflow:20.11-tf2-py3 bash還是
sudo docker run -it --rm --gpus '"device=0:0,1:0"' nvcr.io/nvidia/tensorflow:20.11-tf2-py3 bashAns: 是不連續的,每張卡是獨立的。
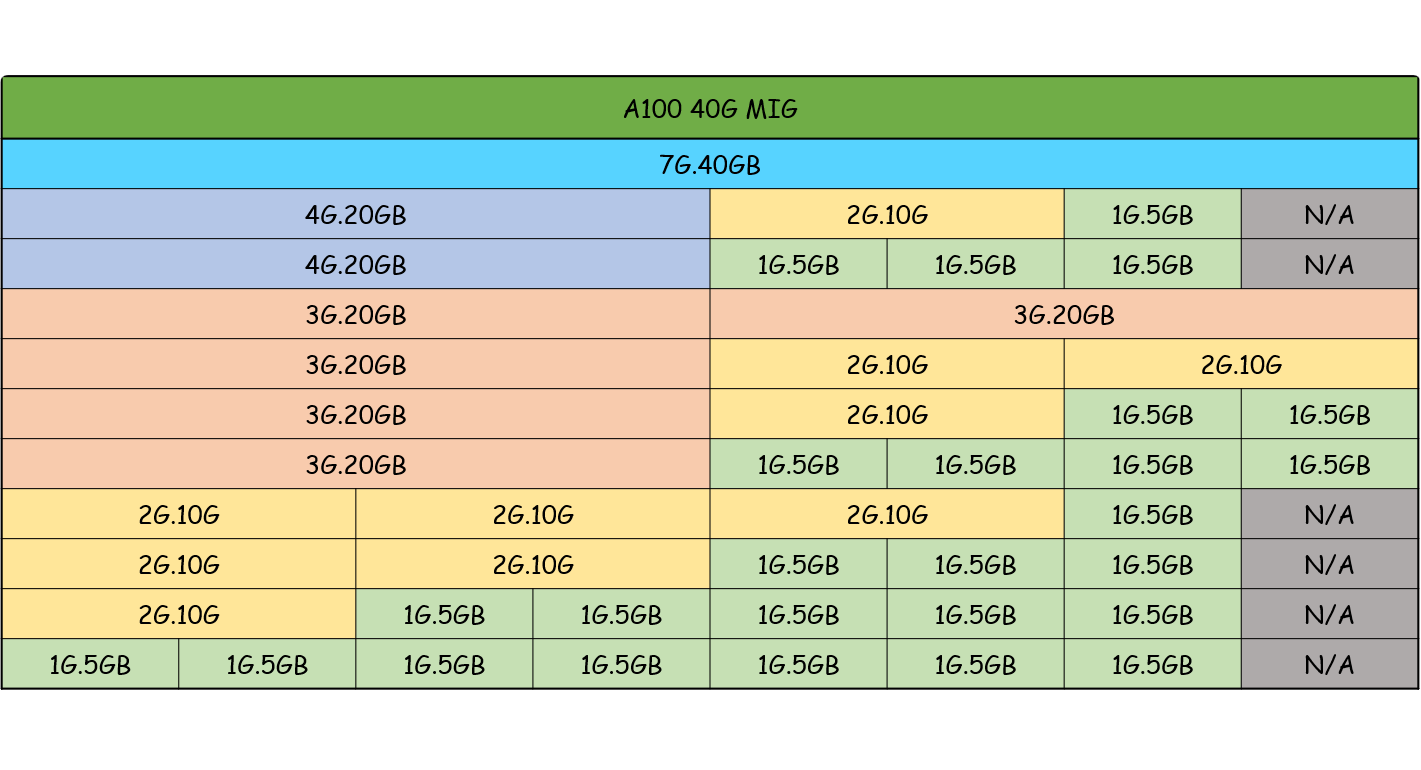
在名詞解釋的部份,有提到: $1 GPU Memory = 8 GPU Memory Slices$ $1 GPU SM = 7 GPU SM Slices$ $1 GPU Slice = 1 GPU Memory Slice + 1 GPU SM Slice$
這是我根據文字描述畫出的簡易component圖:
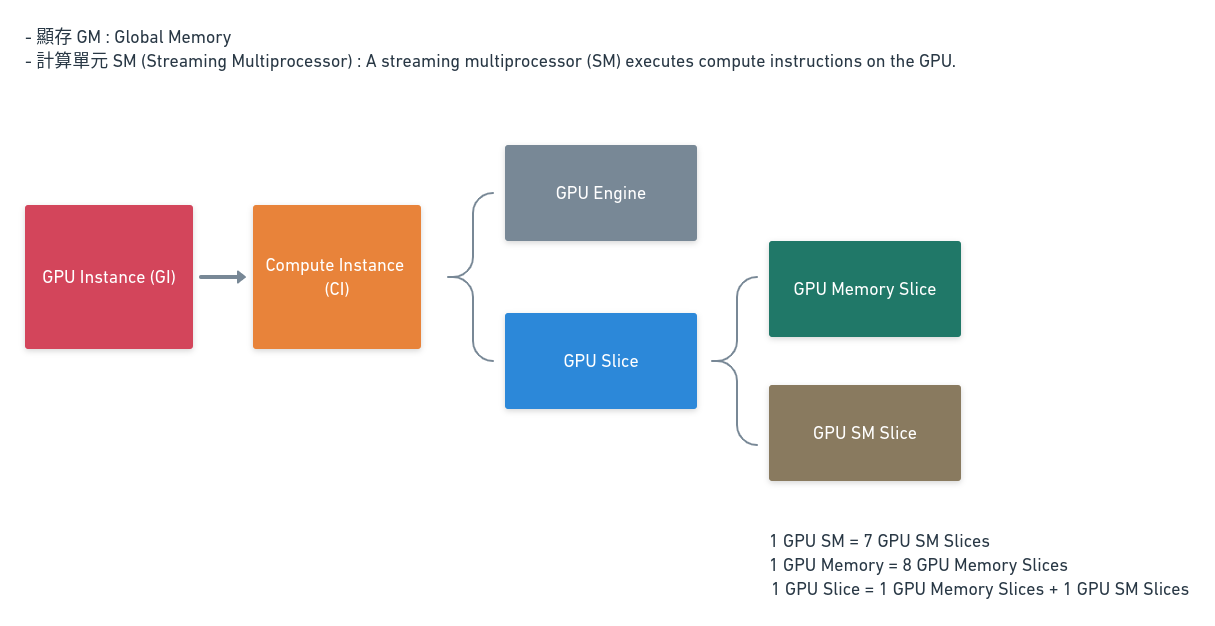
如果按照1個GPU Memory Slice搭配1個GPU SM Slice的方式組成1個GPU Slice,那應該會多1個Memory slice,想請問那個多出來的Memory Slice會被應用在哪個地方?或如何被使用?
Ans: 根據講師說法,其實沒有少一份,但N家它們名詞定義的不是很好,會讓人混淆,所以這部份先跳過。上方名詞解釋部份,只有對應給A100而已。例如A30,其只有24GB,只切給四等分而已。
sudo nvidia-smi -i 0 -mig 1使用指令之後顯示:
Enabled MIG Mode for GPU 00000000:27:00.0
All done.使用指令
nvidia-smi終端器上顯示+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| No MIG devices found |
+-----------------------------------------------------------------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+想請問,其意思是五張A100 GPU卡都一起turn on?還是只有指令上指定的第0張有turn on mode而已?
Ans: 指令使用
-i 0意思是只有第0張GPU有被開啟,我們可以使用nvidia-smi去查看,每張顯卡的最後一欄位,會顯示每張卡的MIG的狀態,default都是Disabled。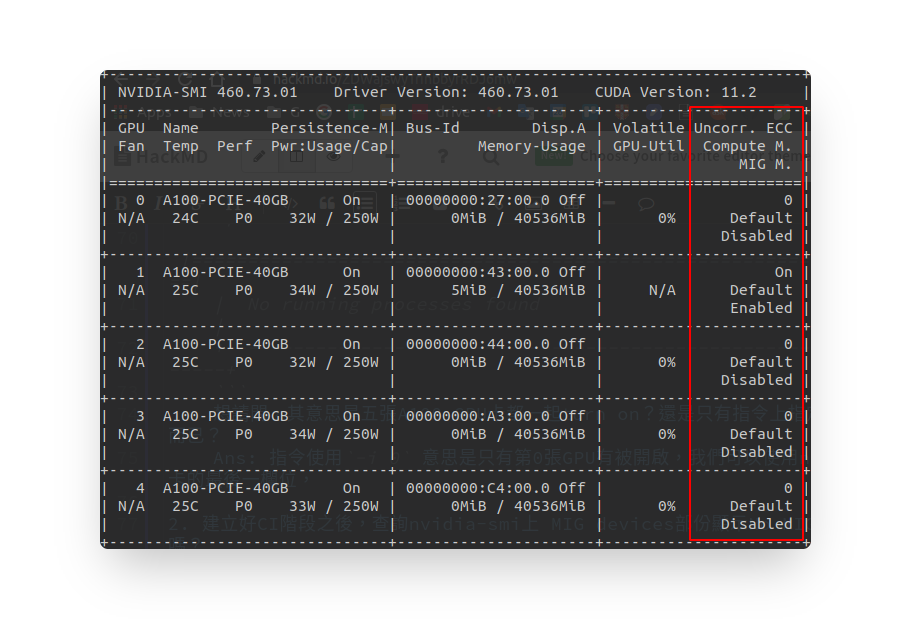
建立好CI階段之後,查詢nvidia-smi上 MIG devices部份顯示No MIG devices found,正常嗎?
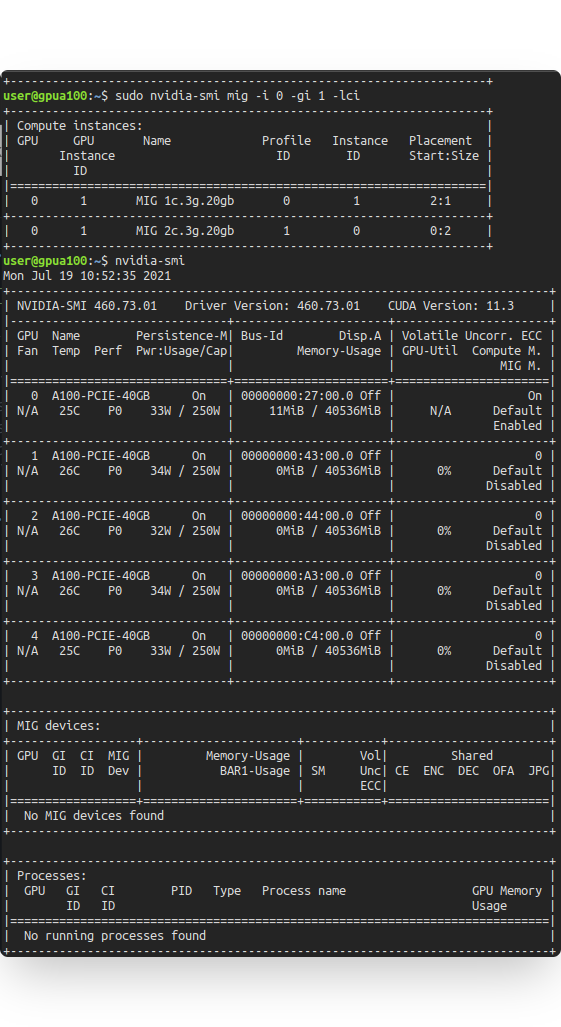
Ans: 已解決,需要使用"sudo"。
承上題,直接嘗試文中使用的指令,會報錯,無法使用。

Ans: 已解決,文中使用的GI跟前文創建不一樣,需要按照所建立的GI&CI使用。
MIG 重點補充整理
對於使用training部份,不建議使用MIG切割,建議使用完整的獨立顯卡。如果是要做多組的inference則適合使用MIG技術。
如果切了許多的MIG,不想要一步一步的關閉,可以直接一次全關(一次disable)。
我們稱此(一個row)為一個mig。
目前平行運算不支援MIG,但k8s支援MIG。平行運算部份,推薦使用horovod。
關機重開之後,並不會自動開起mig分割,要的話就要自行寫腳本來切割,不然就要安裝此插件寫yaml檔。
指令名詞解釋: 假設
sudo nvidia-smi mig -i 2 -cgi 9,其-cgi的c意思是create的意思。當我們
-lgi時,table上會有placement & size,此部份每個mig的start數字是獨立分開,分配也是由gpu指定。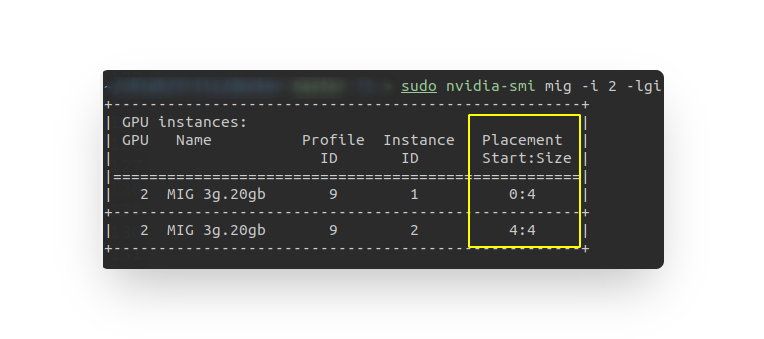
當我們在做CI的切割與分配的時候,我們可以使用
-lcip看組合,每個組合隨GI不同而不同,而CI意思是把每一份MIG再做"算力"切割,GI主要是做memory切割(當然同時也會造成算力被切割),但CI則是做"細部"算力切割使用。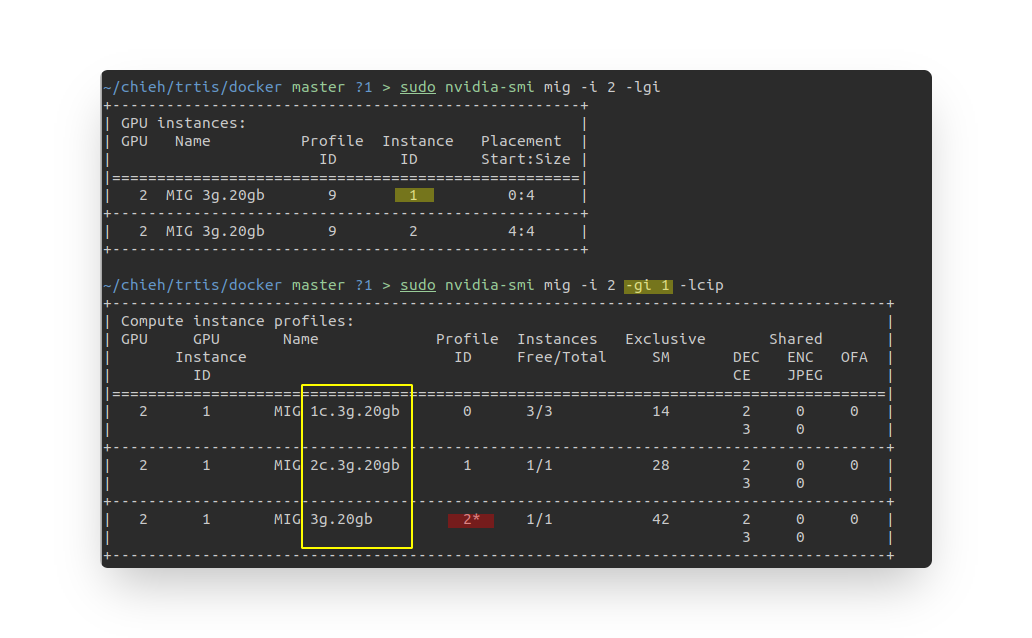
一般都是使用default參數設定
-C。例如:sudo nvidia-smi mig -i 0 -cgi 9 -C。 當切割(CI)之後,還是共享同個memory大小,我們可以於nvidia-smi內看到,只是每個的算力有所不同,而1c或2c就是從3g裡面細切出1份或2份的意思。
切割GPU之後,於Container上使用。
不同張卡裡面的不同CI。
$ docker run --rm -it --gpus '"device=0:1,3:0"' 217a685ca3b1 zsh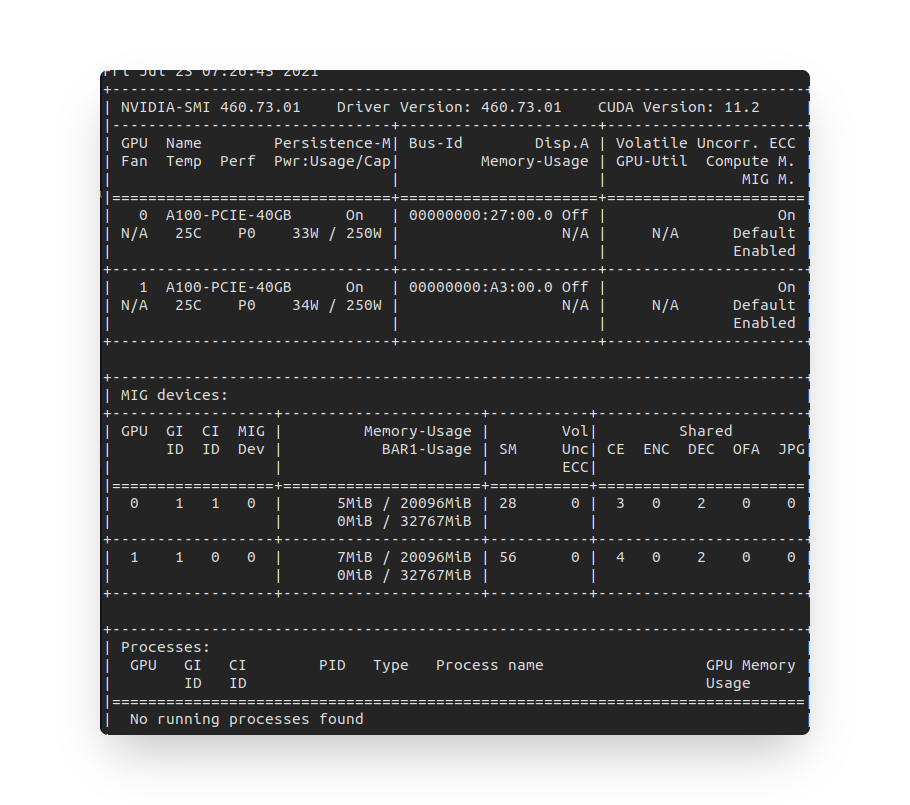
其中一張卡裡的一小CI,搭配一張完整為切卡。
$ docker run --rm -it --gpus '"device=0:1,4"' 217a685ca3b1 zsh
一張卡內切割許多小CI,只取其中兩個CI作為使用。
$ docker run --rm -it --gpus '"device=0:1,0:3"' 217a685ca3b1 zsh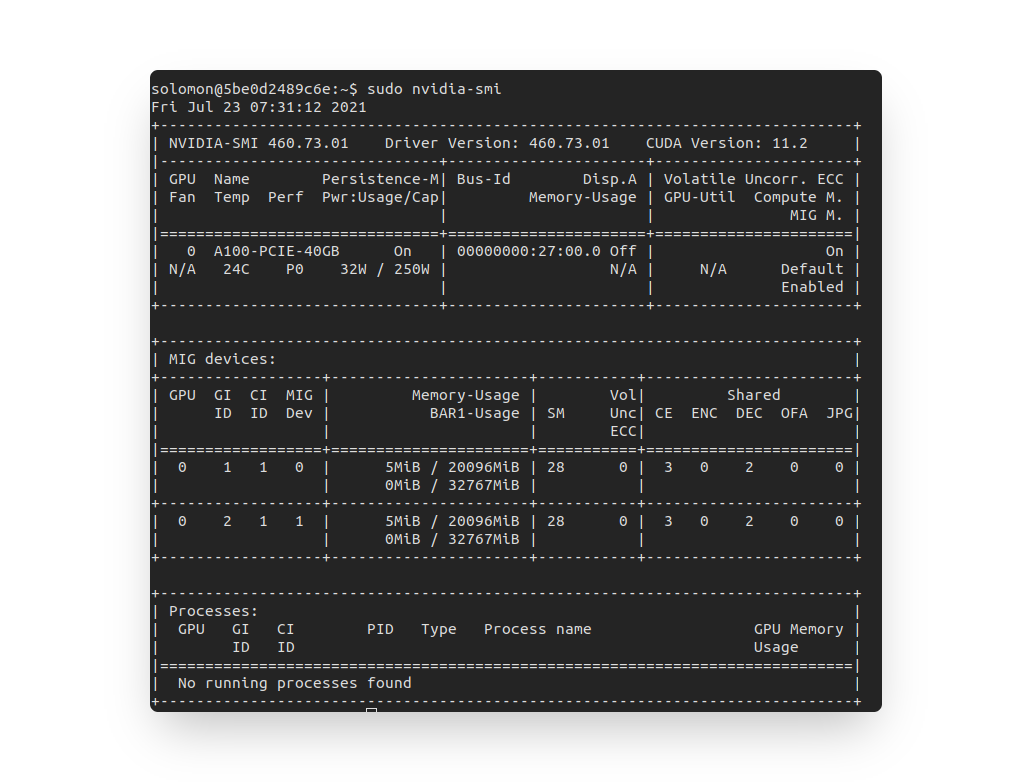
Note
MIG is used on docker and docker-compose file:
當如果重新配置docker-compose file的GPU設置內容部份之後,docker-compose up 若有改變的部份(例如只有其中兩個container的GPU配置有更動),則就會重新創建新的container,言下之意,就是例如密碼等等部份也會重置。
如果docker container assign某一個MIG,當把這個MIG關掉,整張卡關掉(disable -mig 0) MIG功能之後,自動變成allocate整張完整的顯示卡。當重新開啟MIG功能,包含切好(GI, CI)之後,進入container查看nvidia-smi是沒有偵測到GPU的(有配置但不會顯示能使用的記憶體),要重新啟動(e.g., stop > up) 一次之後就會又偵測到之前docker-compose file內所配置給這個container的MIG(前提都沒有動到docker-compose)